




Introduction to the Natural Language Processing System and Hierarchical Document Classification
In a high-turnover academic environment, PDF repositories come with varied formatting, images, tables, and noise that make any automated processing difficult. To address this, we implemented an AI pipeline that combines advanced OCR, structured extraction, and semantic normalization—removing inconsistencies and transforming each document into clean, hierarchical text. This purified content is then sent to our LLM, ensuring:

- Improved accuracy in semantic search;
- Generation of summaries and contextual tags;
- Data consistency for analysis and decision-making.
Context and Objectives
Scope
The diagram below illustrates the data flow selected for implementing the prototype.

- PDF file repository: 89 files, 82,340 words
- No structural standardization: files from different deliverables produced by the 4 participating universities.
Objectives
Perform serial reading of files (pdf, xlsx, markdown, csv), context cleaning, and dimensionality reduction to create specialized prompts for the domain of the uploaded files.
- Preserve academic history: Centralize and organize all versions of requirements, documents, and previous deliverables.
- Efficient onboarding: Enable new participants to access the full project context in seconds, without relying exclusively on senior members.
- Knowledge continuity: Ensure that decisions and lessons learned from past semesters are easy to retrieve and reuse.
- Smart automation: Use AI to automatically index, classify, and hierarchically organize documents in multiple formats (PDF, Excel, Markdown).
- Reduced rework: Minimize duplicated effort when searching for and interpreting artifacts from previous semesters.
Method
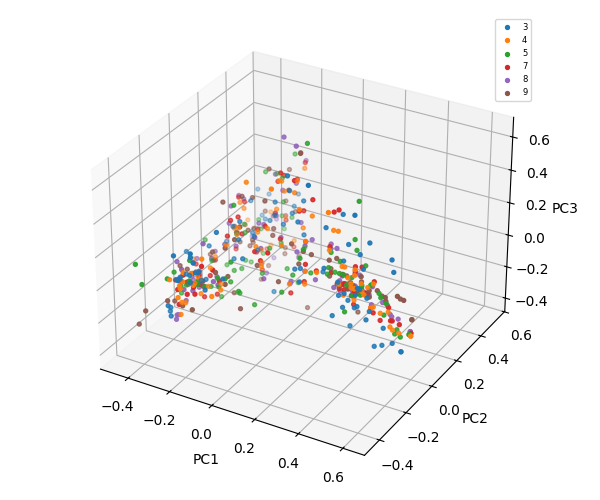
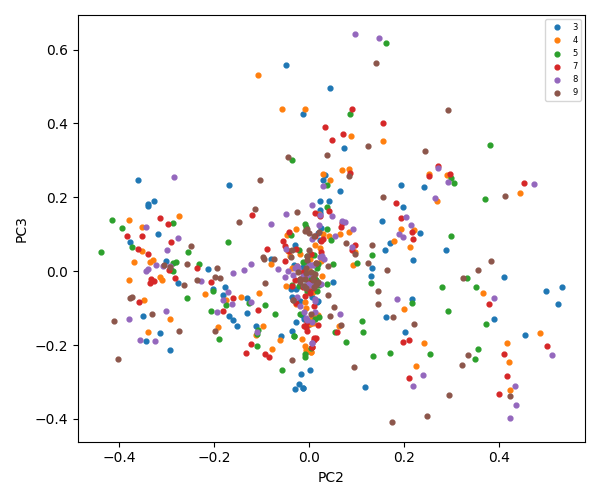
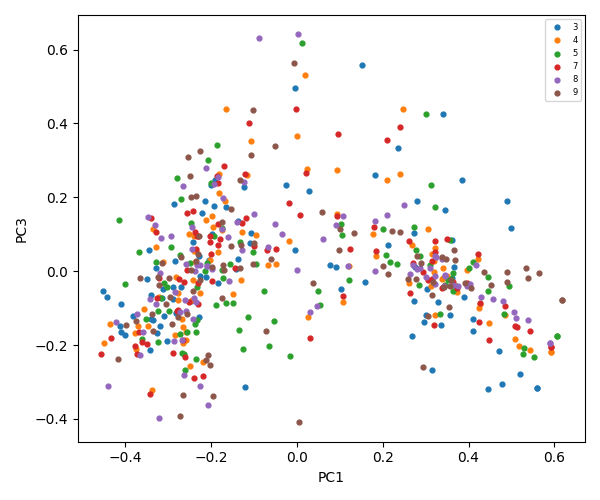
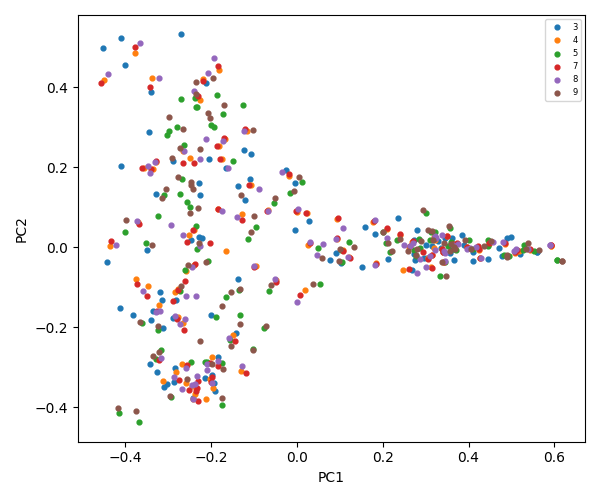
The diagram below illustrates the flow of static analysis of word frequency within files through natural language processing, dimensionality reduction, vectorization, clustering, level-based classification, and feeding the LLM agent with the generated domain data.




- Input: 89 files, 82,340 words
- Output: 89 summarized files, each accompanied by 6 descriptive key phrases.
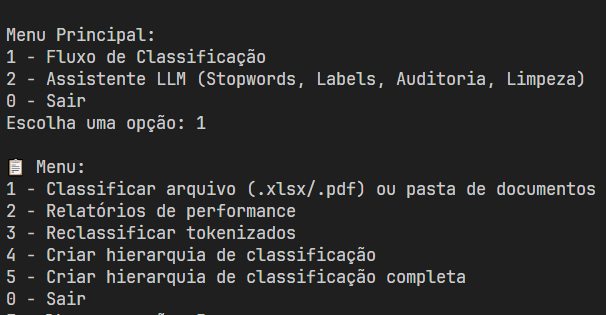
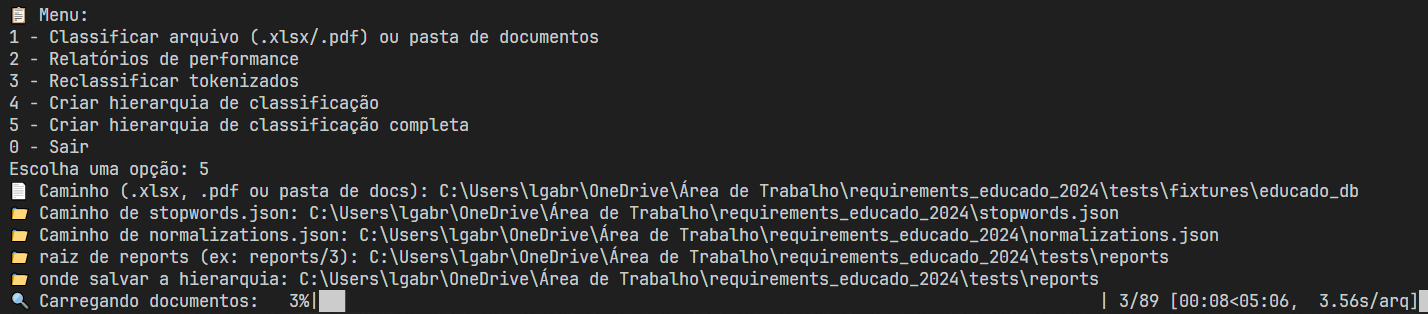
Results
The flowchart below describes the steps of natural language processing, dimensionality reduction, vectorization, clustering, and file classification that generate summaries and inputs for an AI assistant large language model.
- File Classification Algorithm: Folder/file classification algorithm
- Assisted Stopwords Cleaning Algorithm: Assisted learning algorithm for stopword cleaning
- Restricted-domain exploration: Feeding performed through keyword frequency mapping
- Smart automation: Generation of summaries and classification key phrases to feed a file database for Wiki search ALPHA.
- Restricted-domain chatbot: Centralize the LLM’s operation within a clean, restricted data domain. COMING SOON.


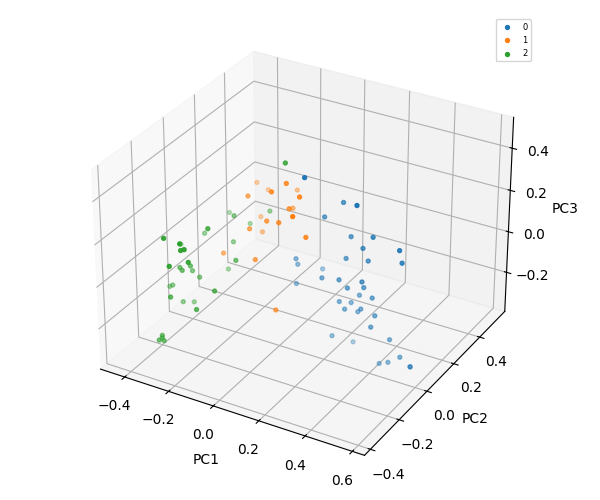
K-Means = 3

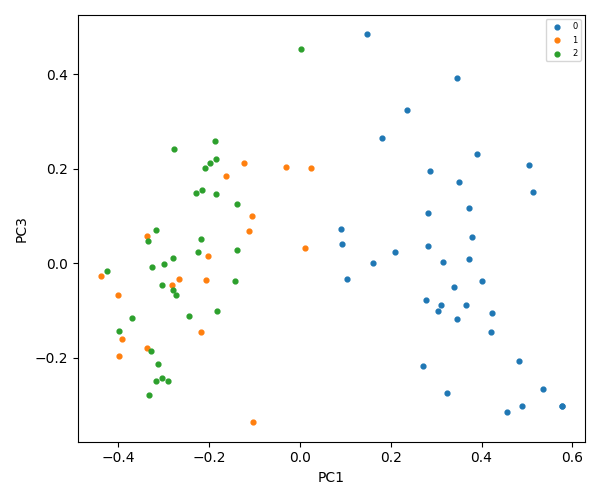
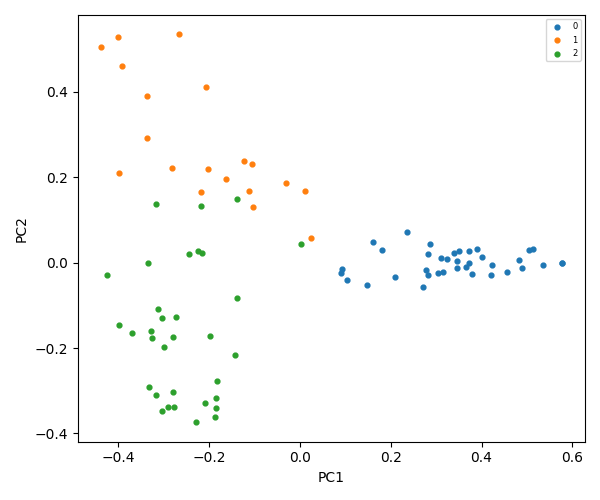
K-Means = 4
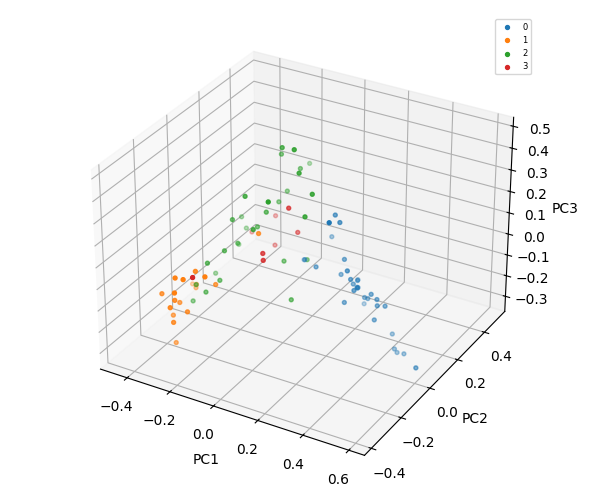


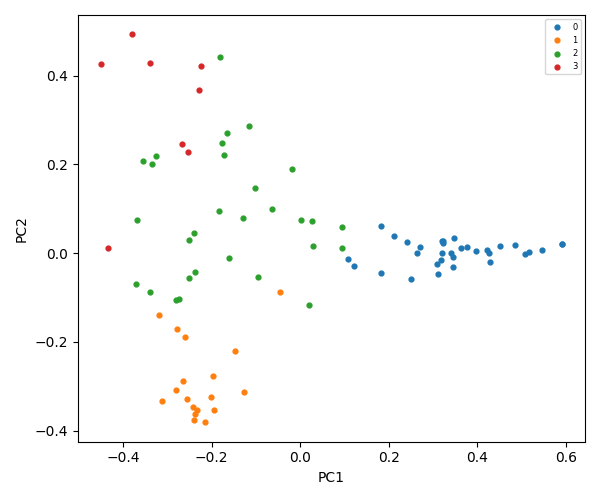
K-Means = 5
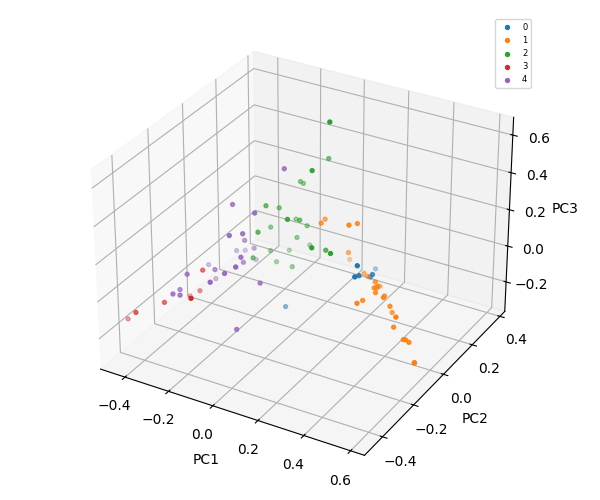
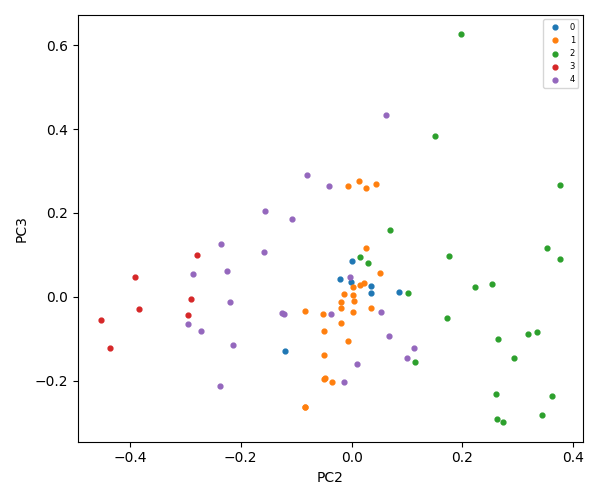
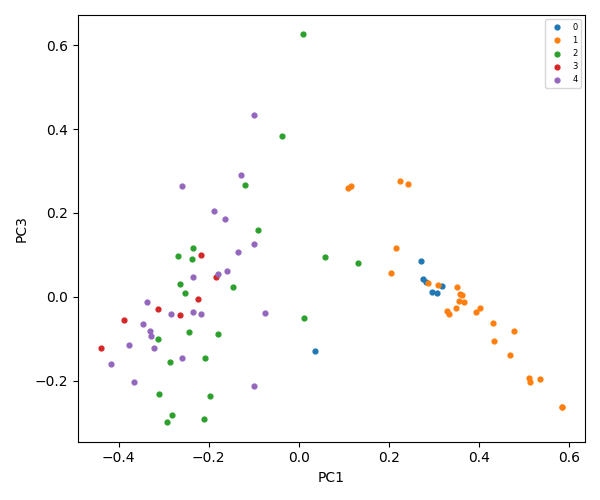
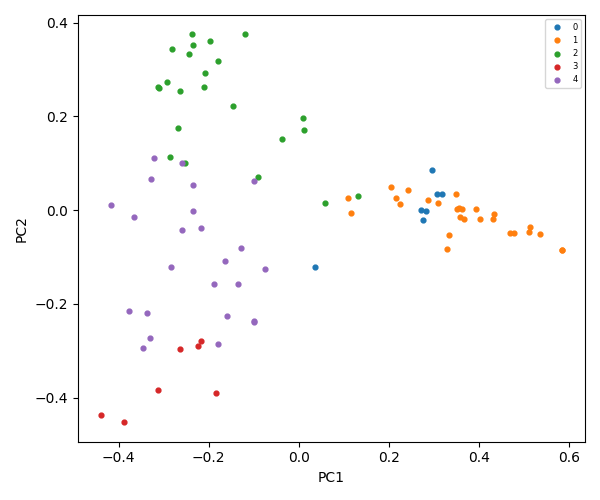
K-Means = 7
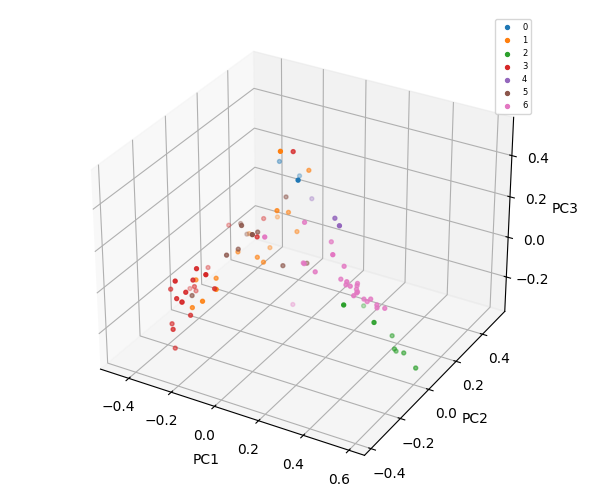
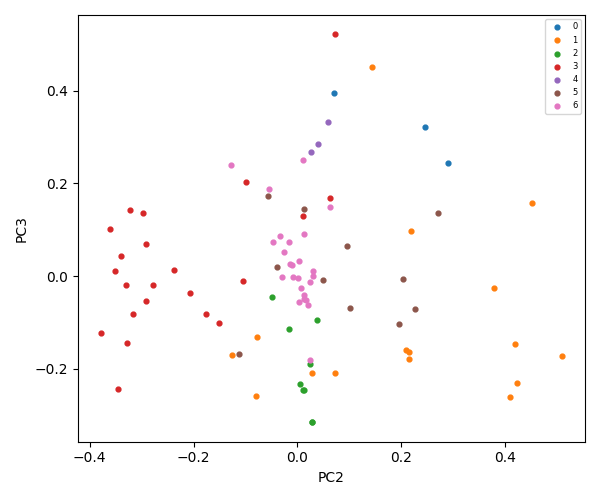
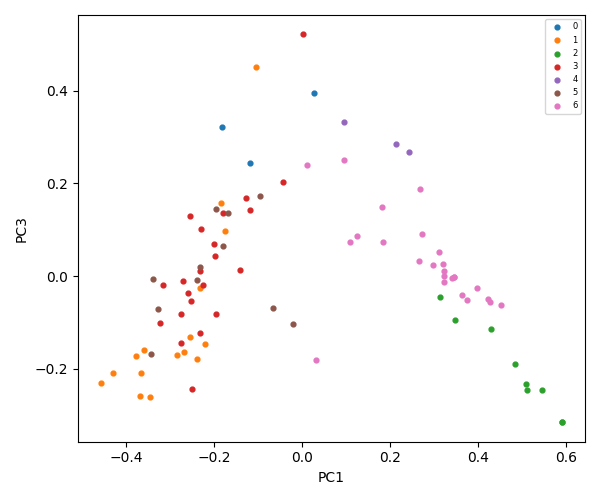

K-Means = 8
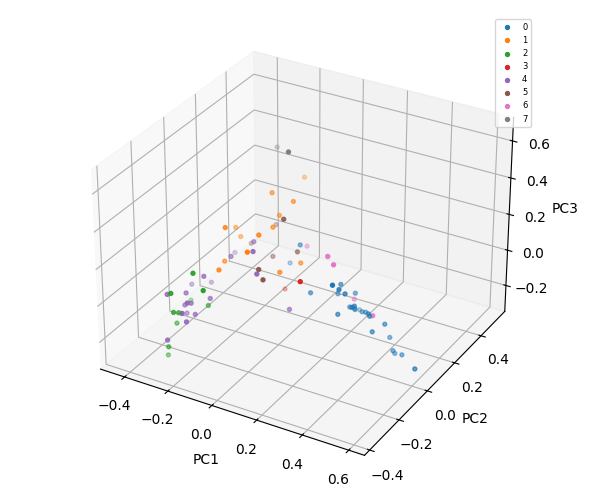
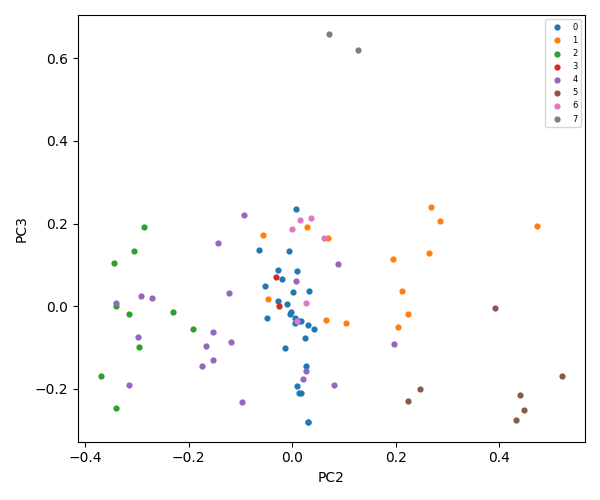
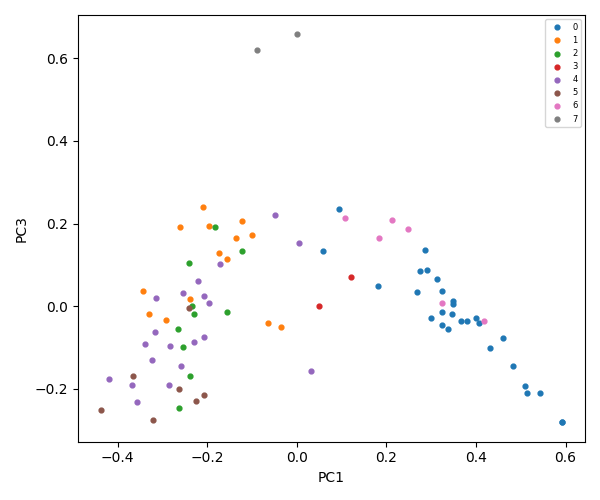
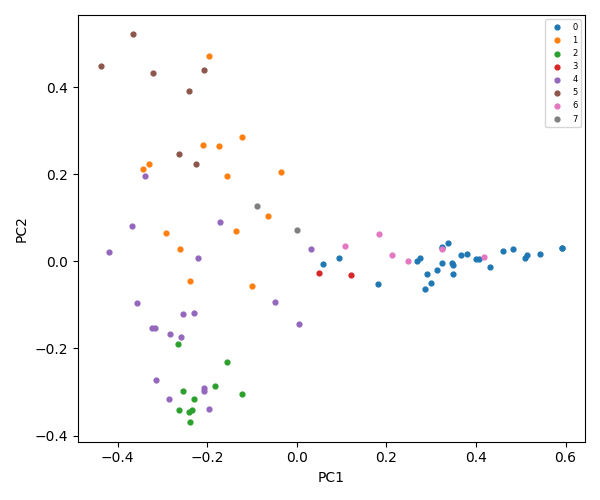
K-Means = 9
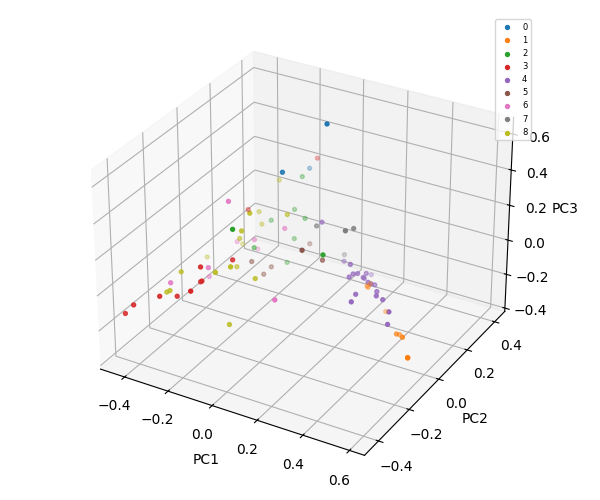



Full exploration
Id: 0
Name: AAU - Mobile Education - 2021 - Final Report - Secure Software Development, Web Security, Injection Attacks & Taint Analysis
Summary: The content addresses secure software development, including vulnerability analysis, cyber and injection attacks, and emphasizes the importance of information security and secure development. It also highlights initiatives focused on mobile education for vulnerable communities, such as building a digital platform for financial education for recyclable material waste pickers.
Labels:
- Secure software development and vulnerability analysis
- Secure software development and cyberattacks
- Secure software development and mobile education for vulnerable communities
- Secure software development and injection attacks
- Development of a digital platform for financial education for recyclable material waste pickers
- Information security and secure development




Next Steps
- Develop and validate an agent performance evaluation system.
- Test scientifically described NLP processes and analyze results.
- Test scientifically described normalization processes and analyze results.
- Test dimensionality reduction processes and analyze results.
- Test vectorization processes and analyze results.
- Test dimensionality plotting procedures and analyze results.
- Test clustering processes and analyze results.
- Test LLM feeding flows and analyze results.
- Evaluate different LLM models and compare performance.
- Draft a compliance checklist for Ready to Use Software Product (RUSP).
References
- Official Educado Documentation (MkDocs)
- Jurafsky, D.; Martin, J. H., Speech and Language Processing, 3rd Edition, Pearson, 2021. (Introduction to NLP techniques)
- MacQueen, J. B., “Some Methods for Classification and Analysis of Multivariate Observations,” in Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, vol. 1, pp. 281–297, 1967. (Original k-means paper)
- Brown, T. B.; Mann, B.; Ryder, N.; et al., “Language Models are Few-Shot Learners,” Advances in Neural Information Processing Systems, vol. 33, pp. 1877–1901, 2020. (Modern LLMs)